
Science has proceeded uninterrupted for hundreds of years now, through its progress we have emerged from ignorance and awakened to the reality of our Universe. But scientific advancement is now retarded by a fundamental problem, the scientists. In the near future something as important as science will no longer be left to imperfect and inefficient biological scientists, but will become be the realm of digital scientists. In this third of Confessions of a Biological Scientist, I will discuss the increasingly digital nature of modern science, and why I see a natural progression towards completely digital scientists.
How do you determine the truth of something? If I were to say something like “All dogs have hair”, what actions would you take to determine the truth of this statement?
Your first course of action with a simple statement such as this, is to devise a counter-example and test to see whether this exists. In the case of my statement that all dogs have hair, the existence of a hairless dog would be adequate to disprove my statement. So you must seek a “hairless dog”. Thus, your next step is going to be to consult a knowledge repository of some sort to see if you can find evidence for a hairless dog.
If it were 100, 50, or even 20 years ago you would have probably started with a book.You might have had a set of encyclopedias in your home, wherein you could turn to the index and look up the term dog. You would probably first look up dog, where it might described them as a “furry friend of man”. At this point you might conclude that dogs all have fur, but being particularly cunning you might also check the index for the term “hairless dog”. And what if your search were to turn up nothing? For the time being, within the given dataset you would have had to conclude that my statement was tentatively true.
Now, it being 2013, you would take a much different tack in addressing the my question. You would simply access a search engine and type in the term “Hairless dog” to see if any such thing exists. Google being as large a data set as we have access to at this point, you can trust that if you can’t find a hairless dog on google, then it probably doesn’t exist. But, you would of course quickly be redirected to the wikipedia page for “Hairless dogs” and you would see that there are actually several breeds listed as hairless.
So at this point you would conclude that my statement was false, and you might devise a counter-statement: Most, but not all dogs have hair.
You have just performed a scientific action. You have taken a hypothesis, devised a confuting example, tested this using a given dataset, and then revised the statement based on this new data. This example also shows just how efficient and fast digital technologies are at testing largest data set ever assembled (ie the internet) to test truth.
This move to digital, searchable knowledge has been a revolution for assessing truth, and has become central to the modern scientific method.
As a scientist, I test scientific statements in the exact same way all of the time. In fact I would never set out to actually do an experiment without first testing it in the literature. As an example, lets say I think that the interaction of two particular proteins might be causing a certain type of cells to die, I must first check google to see what other work has been done on this.
I would examine the peer-reviewed set of scientific knowledge (known generally as “the literature”), and see how much evidence there is to support my particular hypothesis. It is mostly based on this result (and my own proprietary unreleased data), that I will decide whether to proceed with the experiment. I will do a sort of cost-benefit analysis to determine the originality of the experiment versus the likelihood of it working.
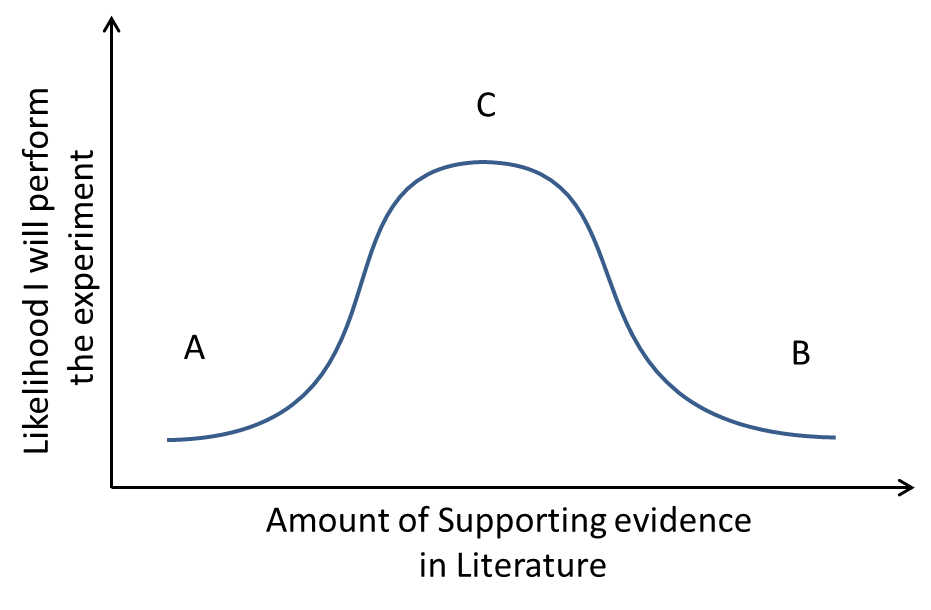
In one situation I might find nothing to indicate that this interaction occurs, or that it has no connection to cell death (marked as A above). In this case, I will likely have to throw away the hypothesis. Unless I already have some strong evidence of my own to suggest that this effect is occurring, I would take the lack of any suggestion as to this effect in the literature as evidence that this is not occurring. Based on this, I would throw away the hypothesis and look in another direction. This experiment is extremely original, but it is very unlikely to work.
Aside: There is an additional reason not to perform such an experiment which has no supporting evidence in the literature. Even if the experiment did happen to work, the fact that there has never been anyone else to suggest this effect would mean that I would have to go to extra lengths to prove my hypothesis. Going out on a limb is only worth it for a particularly juicy hypothesis, risky experiments are only worth it if it will lead to a big finding and an important scientific impact.
Another possibility might be that I find that there already exists overwhelming evidence that these proteins interact and cause this effect (marked as B above). In this case, the experiment is very likely to work but it is totally unoriginal and not really of much value to advancing scientific knowledge. I would simply be repeating experiments for what is already known. Thus, in this situation I would again likely not perform the experiment, rather I would simply cite the interaction of these proteins as scientific fact and move on to a different direction.
Only if an experiment falls into the sweet spot between being completely unknown and completely known would I feel that the hypothesis is justified and I should move on to testing it. Scientists are constantly on the lookout for facts which are balanced between true and false, wherein we can inject a bit of data to tip them in either direction. While the image of scientists is one in a white lab coat with a beaker in hand, the reality is just as likely to be hunched over a keyboard, testing hypotheses using digital tools.
If we think of these types of searches as not just casual googling, but as digital experiments we quickly realize that more science is already more digital world than it is physical one. As this trend continues into the future and becomes increasingly automated, it is only a matter of time until we replace scientists altogether.
So if so much of my work is already a matter of examining digital literature to perform simple testing of hypotheses and cost-benefit analyses to determine what hypotheses might be most advantageous to follow, then what is preventing a computer from performing similar analyses?
The major hurdle that I see for computer systems face today is digesting scientific data which we have encoded in natural human language. As it stands, computers are only beginning to be able to understand what we humans are really saying, but examples like IBM’s Watson show how we are rapidly making strides in accomplishing these ends. As computers are starting to understand the meaning of natural language, I do not think it will be long before a computational strategy develops to try to identify the low hanging fruit of science.
Even as it stands today, we need to perhaps ask how much of this work is really being done by the scientist? If Google is using advanced search techniques to link ideas and thoughts together algorithmically, based on deep learning algorithms, and using a staggeringly vast data set the likes of which a single human could never comprehend, then how much of this is already part of modern science.
It is indisputable that computers are already helping us find the experiments which best hit that sweet spot between originality and likelihood of working. Just as with everything else, the scientific world is naturally becoming more and more digitized. Soon enough, instead of us asking the computers whether this or that experiment is a good ideas, the computers will actually start telling us which experiments to do do, after that it is only a matter of time before they cut out the error prone scientists all together.
Next week I will discuss how we scientists with our lossy natural language and inadequate annotation are holding back this natural digitalization of science, and how we can start to help to put ourselves out of a job. Watch this video and lets meet back here next week.
——–
Interested in writing for Thought Infection? I am looking for contributors and guest bloggers. If you have an interest in futurism and you would like to try your hand at writing for a growing blog, send me an email at thought.infected@gmail.com
